はじめに
こんにちは、ノハナのバックエンドエンジニアの野村です。
弊社のフォトブックアプリ「ノハナ」はサービスのMBaaSなバックエンドとしてParseServerを採用しています。
Parse Serverは元々Parse.comという名前のマネージドなサービスでしたがfacebookに買収された後に終了したので弊社ではParse ServerのOSS版をGCE Instance group環境でセルフホストしています。
その経緯は↓の記事をご覧ください。
ありがとう、さようなら Parse.com。ノハナがParse.comと共に過ごした4年間の話
また、元々Parse Server以外の各機能のサービスをGKEで運用しており、色々と課題が出てきたこのタイミングで既存GKE環境に新たに参加させることとしました。
この記事ではアーキテクチャ内容や移行方法などを記載していこうと思います。
旧アーキテクチャ
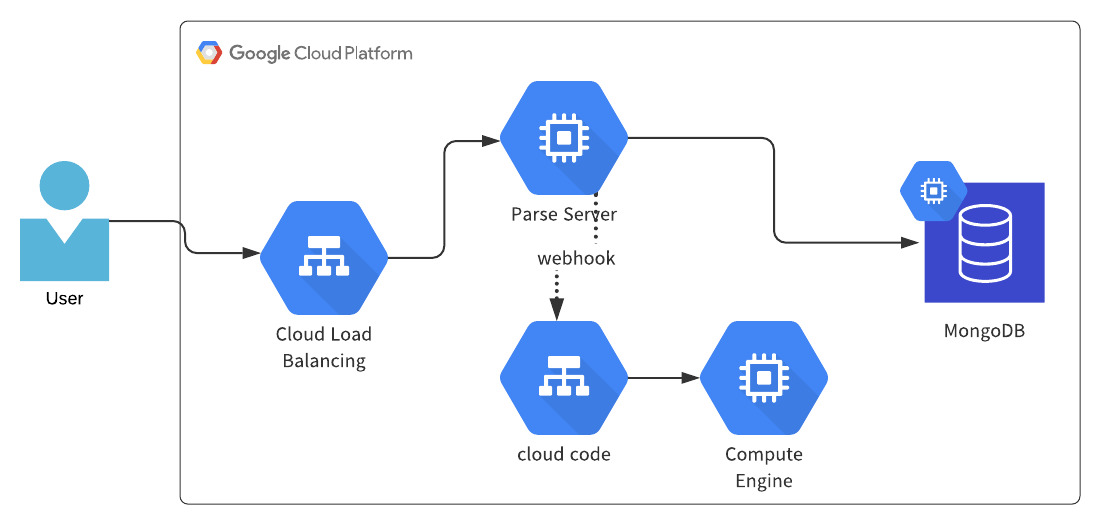
旧アーキテクチャはGoogle LoadbalancerのバックエンドとしてGCE Instance group上にアプリケーションをホストしています。
Parse Serverはデフォルト状態ではデータのCRUDリクエストだけを扱うフレームワークなので、決済処理などアプリ固有の特殊なことをしたい場合にはParse ServerのCloud Code Webhooks機能というものを使います。
Cloud Code Webhooks機能とはParse Serverに対して/functionsネームスペースのパスでリクエストすると、Parse Serverが処理をするのではなくcloud codeサーバにコンテキストを含んだリクエストをさらに送り処理を委任する仕組みです。
旧アーキテクチャの課題
メンテナンス性
VMとしてホストしているのでOS更新やパッチなどアプリ以外の手間がかかります。これはマネージドなk8sであるGKEに移行することで解消できると思います。
ソースコードのリリース自体も手作業の部分があり課題に感じています。
こちらは後述します。
インフラ費用
オートスケール設定をしていますが、アイドリング時のインスタンスは確保しています。
1VM/1アプリなので必ずしも負荷に対して必要最小数のリソースを確保できているわけではなく、多くの場合はオーバースペックなリソースが常に確保されていて費用に影響します。
こちらも既存GKE環境の同じNode Poolに参加させ、空きリソースを埋める形で費用の最適化が図れるはずです。
新アーキテクチャ

Google Loadbalancer + NEG + GKEの構成にしました。
GKE側で用意したServiceをアタッチしたNEG backendを既存のLoadbalancer Url Mapに紐づける構成です。
以下詳細説明します。
Google Loadbalancer + Network endpont group + GKE
Google Loadbalancerは単一のリソースではなく各機能ごとにForwarding Rule,Target Proxy,Url Mapといったリソースで構成されています。旧アーキテクチャではUrl MapにGCE Instance groupをバックエンドサービスとして紐付けていました。
新アーキテクチャではNetwork endpoint group(NEG)をバックエンドサービスとして紐付けます。
ちなみにNEGを使うとGKE以外にもCloud Run,GAE, Cloud Funciotionsをバックエンドサービス化することが可能になります。
ドメイン名解決
VPC内部でリクエストが発生するCloud Code webhooks機能のため、Parse Serverがcloud codeサービスがどこにあるのかドメイン解決をしなければいけないという事情がありました。
旧アーキテクチャのGCE Instance groupではPrivate DNSを利用しています。
今回はHostAliasesを利用して解決しました。
HostAliasesにIPアドレスとホスト名の対応を記述すると、/etc/hostsにエントリーが追加されてPodレベルでのドメイン解決をすることができます。

上記により、移行作業中に新旧アーキテクチャを同時に存在させることが可能になり、ノーメンテナンスでの移行が可能になりました。
terraform, k8s manifest
どこまでをterraformに任せるべきか迷うところですが、ざっくりGCPの世界はterraform, k8sの世界はk8s manifestに分けることとしています。
terraformが設定する主な項目
- Loadbalancerの各種リソース
- forwarding rule, url map, target proxy, backend service
- 外部IPアドレス
- ヘルスチェック設定
- k8s namespace
k8s manifestが設定する主な項目
- サービス関連
- Deployment, Service(ClusterIP), HPA
- Secret
- NEG
GKEために使用するNEGを作成するにはk8s側のService manifestに設定を追加します。詳しくは公式を見てください。
CI/CD
旧アーキテクチャでは下記方法でソースコードのリリースを行ってました。
GitHubに差分をpushする- ステートフルなVMにsshしてその環境下で
ansible playbookを叩いてDisk Imageまで作る - GCPコンソールで
Instance Templateを作って対象のInstance Groupを更新する
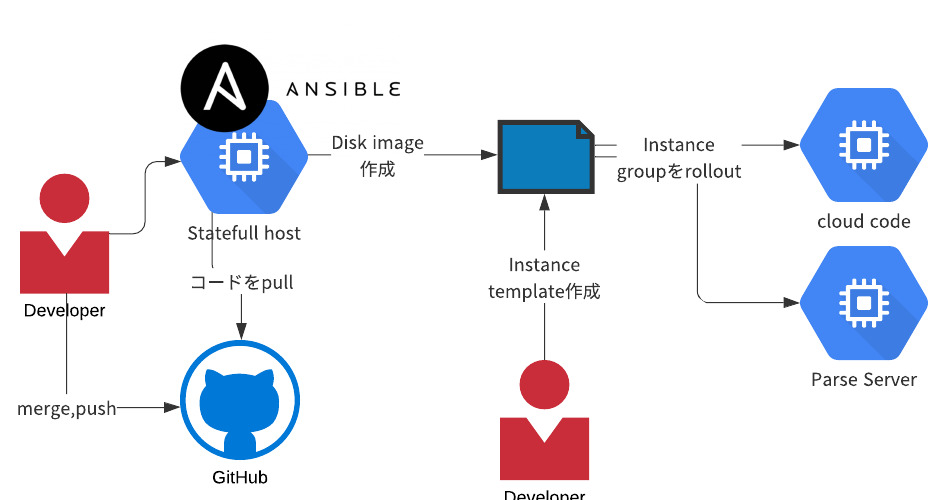
AnsibleがあることでIaCしてると言うことはできますが、結局は各所の手作業がオペミスの温床になってしまっています。
新アーキテクチャではCircleCIでCI/CDを行います。検証環境/本番環境など各環境用と対応するgitブランチのprefixを定義し手作業なしでデプロイまで一貫して行うGitOpsを取り入れています。
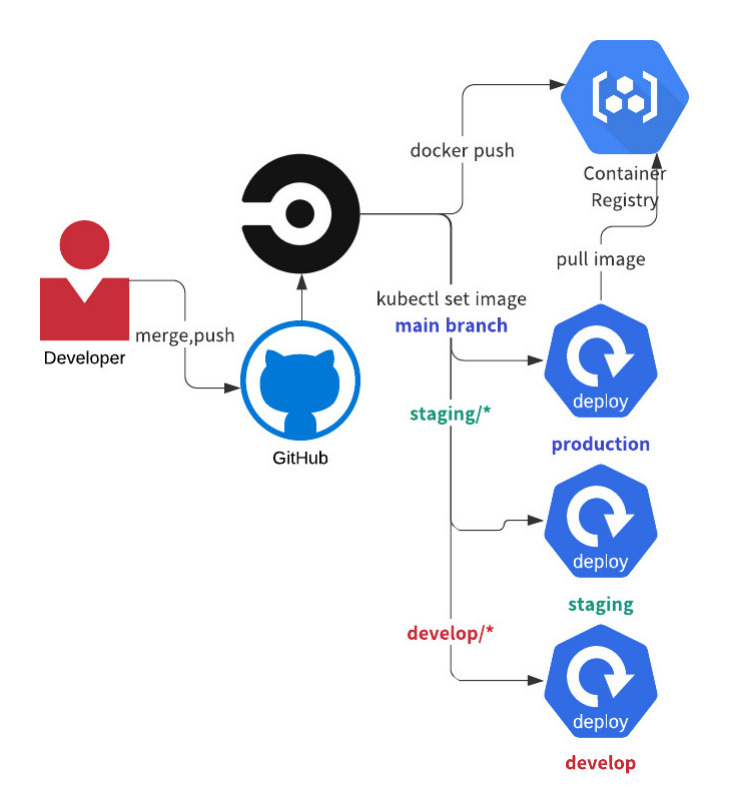
該当prefixのmerge,pushが発生すると該当するCircleCI Workflowが動きます。本番環境の場合はCircleCIのManual job approveを利用しています。そのタイミングだけは敢えてボタンクリック程度の手作業は介在するようにはしています。
原理的には必要なさそうですが、念の為の措置です。
負荷テストについて
新しいアーキテクチャをリリースするにあたって旧アーキテクチャと同程度の負荷に耐えられるか検証する必要があります。
目標の設定
旧アーキテクチャのアクセスログやモニタ結果からレイテンシ,最頻のリクエストパス,メソッドを解析しました。
解析対象のデータはCloud Monitoring,Cloud Loggingから取得できるものを利用しました。
Parse Serverへのリクエストパターンは前述したCRUD,Cloud Code Webhooksに加えて/filesがあります。
/filesは画像などファイルのアップロード時のエンドポイントです。
(仕様上は他にもあるのですがサービスで使ってるのは主にこのパターンです。)
Cloud Code Webhooksの場合はparse →cloud codeとVPC内通信のオーバヘッドも存在します。
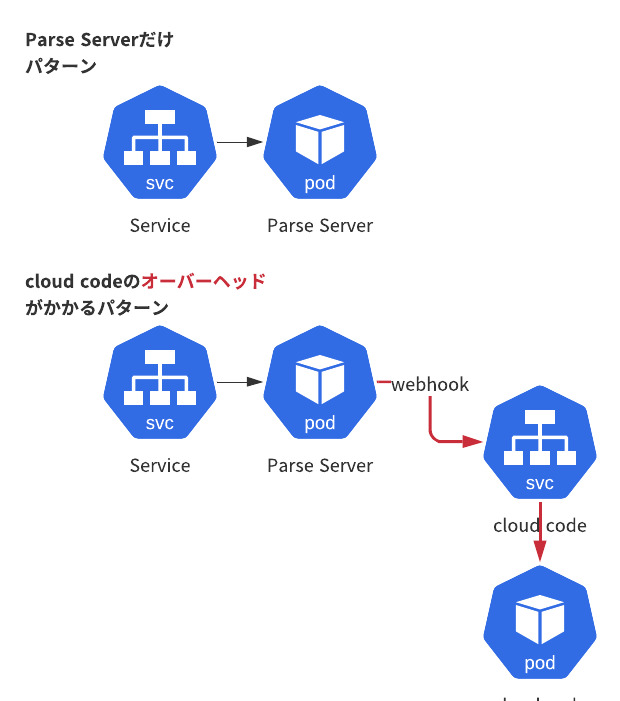
上記の前提と解析した最頻リクエストを元に負荷テストのサンプルとして対象となるリクエストパターンを下記のように設定しました。
各種リクエストボディ、レスポンスボディのデータ量は解析した最頻リクエストの中央値を設定しました。
Parse Serverだけで完結する単純なCRUDcloud codeサーバーを経由するもの(Cloud Code Webhooks)/filesでの画像アップロード
目標を踏まえた観点
解析した各リクエストが同等のレイテンシとなるかどうかが主な観点なのですが、新アーキテクチャだと1発目では目標を達成できないことが想定されています。
弊社サービスは月末無料クーポンや季節の表紙デザインといった時期イベントがあるため、月中や月末月初にリクエストが集中する傾向にあります。
加えて必要最小限のインスタンス数で運用する方針などなど諸々の事情を踏まえ、平常時は最小限のインスタンス数で稼働するが、急な負荷に耐えられる感度が達成できるかもチェックをしました。
まとめるとこんな観点
- 旧環境と同じ負荷をかけた場合に各リクエストのレイテンシが許容範囲か?
- 適切にオートスケールするか?
テスト実施方法
実施環境
単純にインターネット越しにリクエストをすると、Loadbalancerのエッジなどk8s環境以外の通信経路の要因がテストに影響するため、k8s内でリクエストが完結するように負荷テスト用のPodからテスト対象のService IPに向けて実施することとしました。
# 永久に立ち上げたいのでsleep infinity kubectl run --restart=Never for-test --image=golang -n parse --command sleep infinity
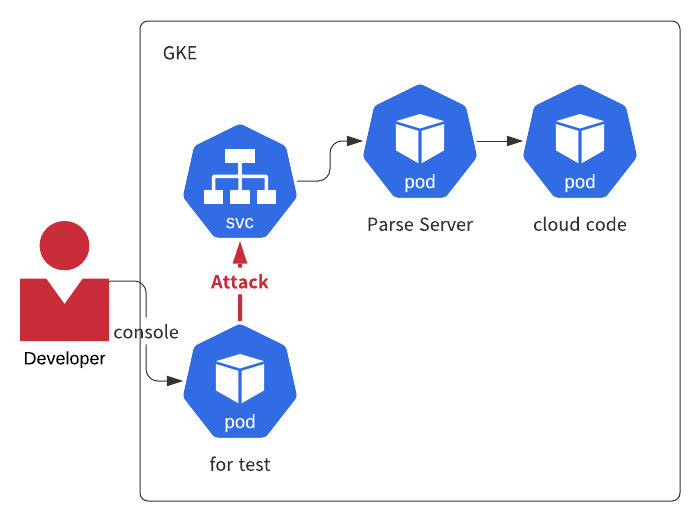
vegeta
ストレスツールにはvegetaを使いました。
コマンドラインでテスト実施からレポートまで完結できる使いやすいツールです。Go製で小さいバイナリなのも特徴です。
kubectl exec -it for-vegeta -n parse -- bash # コンテナ内でvegetaをinstall go get -u github.com/tsenart/vegeta
テスト実施例
vegeta attack -duration=60s -workers=600 -rate=600/s -targets=test.txt | vegeta report Requests [total, rate, throughput] 36000, 600.02, 590.94 Duration [total, attack, wait] 1m0.920396805s, 59.997965107s, 922.431698ms Latencies [mean, 50, 95, 99, max] 864.723553ms, 834.944781ms, 1.032921586s, 1.386483407s, 2.990366358s Bytes In [total, mean] 6048000, 168.00 Bytes Out [total, mean] 7463340000, 207315.00 Success [ratio] 100.00% Status Codes [code:count] 200:36000 Error Set:
test.txt内容
POST http://path-to-parse/functions/some @test.json
チューニング
負荷テストを実施した結果、改善点が見つかったため下記チューニングを実施しました。
Machine Type
GKEはk8s node-poolのNode VMのmachine typeを指定することができます。
E2 共有コア VMのe2-mediumを指定しました。E2共有コアはCPUバーストで規定時間だけ規定vCPUを超えて最大2コアまで使用することができます。
CPUバーストで使える最大コアはGKEのPodのresources.limits.cpuにあたります。
ただし時間限定のバーストのため、resource.requests.cpuには当てはまらないため、バースト分だけPodを詰め込めるというわけではありません。
各deploymentのrequest cpu
当初は各コンテナのresource.requests = cpu: 200mを指定していました。
しかし、Serviceごとに負荷に対するCPU消費量の顕著な違いがあったため最適化させるチューニングを行いました。
最適化させる指標はkubectl top podの結果を参考にしました。
kubectl top pod -n parse NAME CPU(cores) MEMORY(bytes) parse-server-5c6ddd8d99-j5g9b 95m 102Mi parse-server-files-5b7f9b96d6-7swgr 82m 150Mi photobook-cloudcode-7d47f4fb66-xqh46 350m 47Mi
Serviceの分割
同じSerivce内で「CPU消費量が比較的小さくて旧アーキテクチャでのリクエスト数が大きい」条件を満たすエンドポイントが存在していました。そういったものは独立したServiceとすることで、インフラ費用対効果を高めました。

既存→新規アーキテクチャのノーメンテナンス移行
移行は新アーキテクチャを一式用意した上でLoadbalancerのBackendを旧→新に切り替える方法で行いました。作業はGCPコンソール上で行いました。

作業完了後にログを確認してると、設定後一斉にリクエストが新環境のバックエンドに向けられるわけでなく少しずつ新環境のリクエストが増えてることがわかりました。
おそらく各拠点のエッジへの浸透速度のギャップがあるのだろうと思います。
移行した感想
旧アーキテクチャでステートレスに作ってくれていた
旧アーキテクチャではInstance groupに実装されていたこともあり、アプリ自体はステートレスに作られていました。
そのためコンテナ化自体はスムーズでした。
その一方で設定をファイルに記述するタイプのアプリケーションはk8s,コンテナ化に対して相性悪いなあという感想を抱きました。
ローカル環境で動かす際のセットアップやk8sのSecretとで設定方法に差異が生じるため、各所で微妙な手作業のコストやセットアップの難易度が上がるのが理由です。
今回は既に動いているもののリアーキテクチャだったので選択の余地はありませんでしたが、新規でアプリのフレームワークごと選定する際は、ローカルとリモートの条件がなるべく同一となるような設定の組み立て方を考慮した方が良いと思います。
LB + NEGの可能性
Google HTTS(S) Loadbalancer + NEGという構成は冒頭の説明の通りCloud Run,Cloud Functions,GAEなどサーバレス環境もハイブリッドに紐付けることができるので、費用や運用面でいろんな可能性を考えることができます。
まとめ
今回のリアーキテクチャで開発環境に蔓延る職人的な要素がかなり改善でき、開発作業、リリース作業の民主化が図れたと思います。そういった箇所をどんどん増やしていくことで開発効率も改善されて、もっとユーザーにバリューを与えるソースコードを書いていけるようになるんじゃないかなと期待しています。